pooler
Table of Contents
- Table of Contents
- Overview
- Setup
- State transitions and data composition
- Major Components
- Development setup and instructions
- Monitoring and Debugging
- For Contributors
- Phase 2 Quests: A Case Study of Implementation
- Find us
Overview
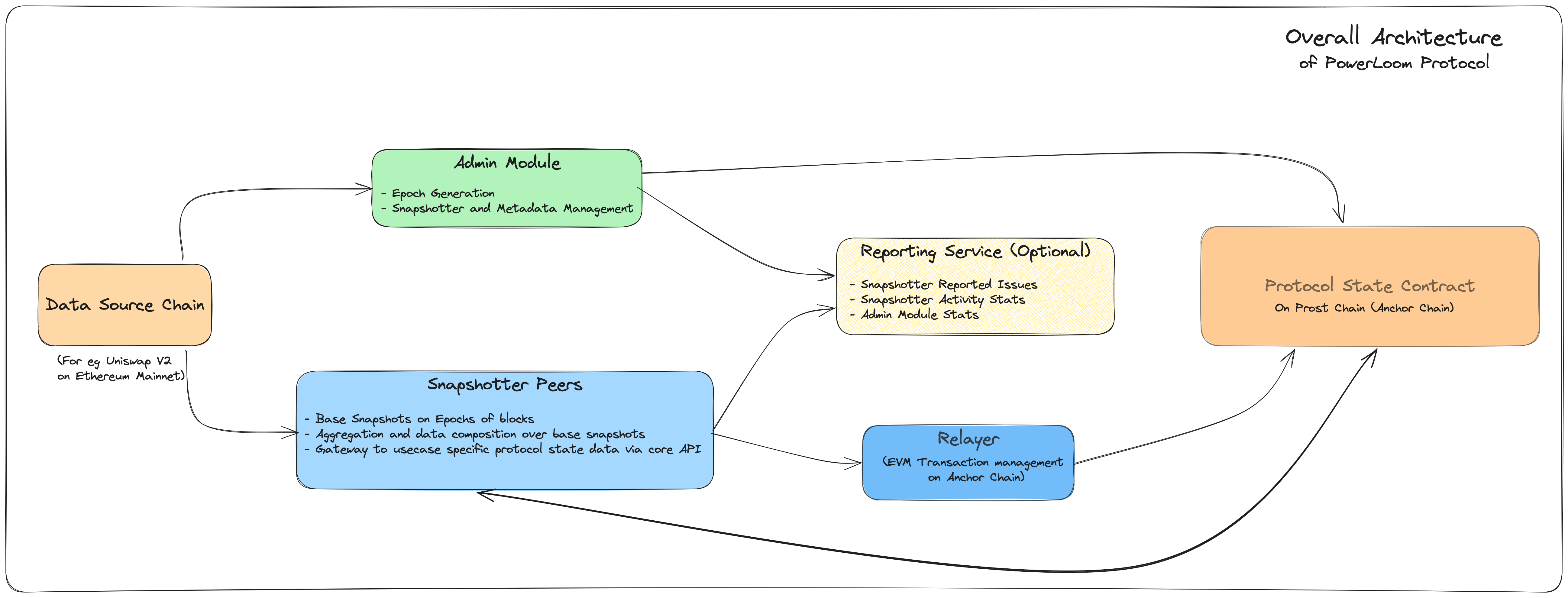
A snapshotter peer as part of Powerloom Protocol does exactly what the name suggests: It synchronizes with other snapshotter peers over a smart contract running on the present version of the PowerLoom Protocol testnet. It follows an architecture that is driven by state transitions which makes it easy to understand and modify.
Because of its decentralized nature, the snapshotter specification and its implementations share some powerful features that can adapt to your specific information requirements on blockchain applications:
- Each data point is calculated, updated, and synchronized with other snapshotter peers participating in the network
- synchronization of data points is defined as a function of an epoch ID(identifier) where epoch refers to an equally spaced collection of blocks on the data source blockchain (for eg, Ethereum Mainnet/Polygon Mainnet/Polygon Testnet – Mumbai). This simplifies the building of use cases that are stateful (i.e. can be accessed according to their state at a given height of the data source chain), synchronized, and depend on reliable data. For example,
- dashboards by offering higher-order aggregate datapoints
- trading strategies and bots
- a snapshotter peer can load past epochs, indexes, and aggregates from a decentralized state and have access to a rich history of data
- all the datasets are decentralized on IPFS/Filecoin
- the power of these decentralized storage networks can be leveraged fully by applying the principle of composability
Architecture
The Snapshotter Peer is thoughtfully designed with a modular and highly configurable architecture, allowing for easy customization and seamless integration. It consists of three core components:
- Main Snapshotter Codebase:
- This foundational component defines all the essential interfaces and handles a wide range of tasks, from listening to epoch release events to distributing tasks and managing snapshot submissions.
- Configuration Files:
- Configuration files, located in the
/configdirectory, play a pivotal role in defining project types, specifying paths for individual compute modules, and managing various project-related settings.
- Configuration files, located in the
- Compute Modules:
- The heart of the system resides in the
snapshotter/modulesdirectory, where the actual computation logic for each project type is defined. These modules drive the snapshot generation process for specific project types.
- The heart of the system resides in the
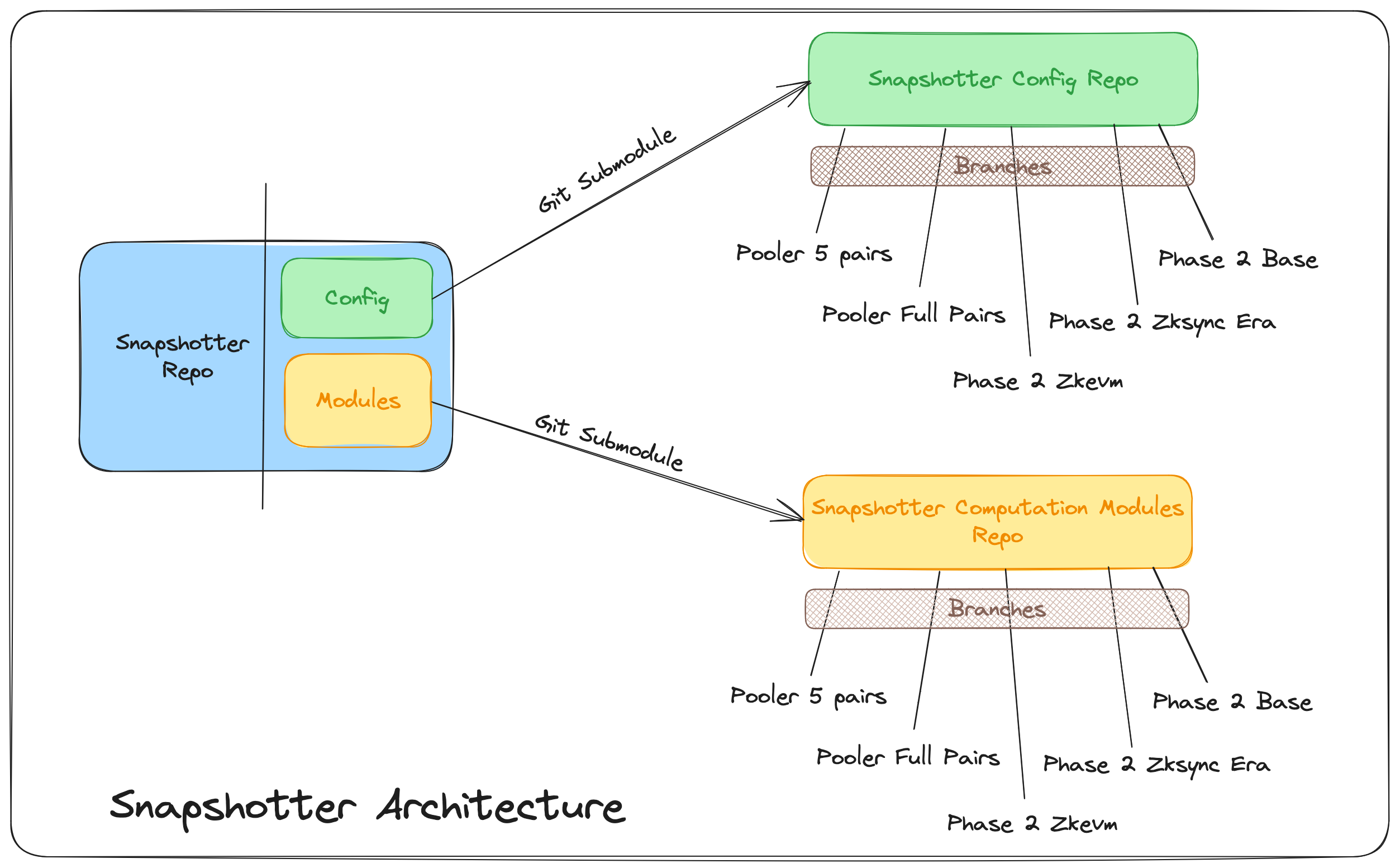
The architecture has been designed to facilitate the seamless interchange of configuration and modules. To achieve this, we maintain these components in separate Git repositories, which are then integrated into the Snapshotter Peer using Git Submodules. As a result, adapting the system to different use cases is as straightforward as changing a Git branch, offering unparalleled flexibility and versatility.
For more information on using Git Submodules, please refer to the Git Submodules Documentation.
Setup
The snapshotter is a distributed system with multiple moving parts. The easiest way to get started is by using the Docker-based setup according to the instructions in the section: Development setup and instructions.
If you’re planning to participate as a snapshotter, refer to these instructions to start snapshotting.
If you’re a developer, you can follow the manual configuration steps for pooler from this document followed by the instructions on the deploy repo for code contributors for a more hands-on approach.
Note - RPC usage is highly use-case specific. If your use case is complicated and needs to make a lot of RPC calls, it is recommended to run your own RPC node instead of using third-party RPC services as it can be expensive.
State transitions and data composition
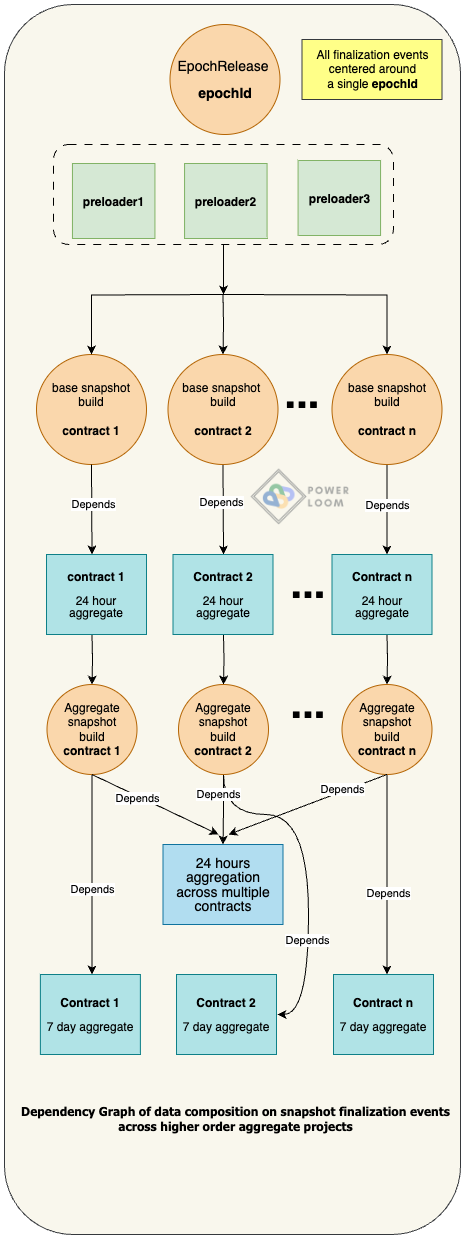
Epoch Generation
An epoch denotes a range of block heights on the EVM-compatible data source blockchain, for eg Ethereum mainnet/Polygon PoS mainnet/testnet. This makes it easier to collect state transitions and snapshots of data on equally spaced block height intervals, as well as to support future work on other lightweight anchor proof mechanisms like Merkle proofs, succinct proofs, etc.
The size of an epoch is configurable. Let that be referred to as size(E)
-
A trusted service keeps track of the head of the chain as it moves ahead, and a marker
h₀against the max block height from the last released epoch. This makes the beginning of the next epoch,h₁ = h₀ + 1 -
Once the head of the chain has moved sufficiently ahead so that an epoch can be published, an epoch finalization service takes into account the following factors
- chain reorganization reports where the reorganized limits are a subset of the epoch qualified to be published
- a configurable ‘offset’ from the bleeding edge of the chain
and then publishes an epoch (h₁, h₂) by sending a transaction to the protocol state smart contract deployed on the Prost Chain (anchor chain) so that h₂ - h₁ + 1 == size(E). The next epoch, therefore, is tracked from h₂ + 1.
Each such transaction emits an EpochReleased event
event EpochReleased(uint256 indexed epochId, uint256 begin, uint256 end, uint256 timestamp);
The epochId here is incremented by 1 with every successive epoch release.
### Preloading
Preloaders perform an important function of fetching low-level data for eg. block details, and transaction receipts so that subsequent base snapshot building can proceed without performing unnecessary redundant calls that ultimately save on access costs on RPC and other queries on the underlying node infrastructure for the source data blockchain.
Each project type within the project configuration as found in config/projects.json can specify the preloaders that their base snapshot builds depend on. Once the dependent preloaders have completed their fetches, the Processor Distributor subsequently triggers the base snapshot builders for each project type.
https://github.com/PowerLoom/pooler/blob/5e7cc3812074d91e8d7d85058554bb1175bf8070/config/projects.example.json#L3-L12
The preloaders implement one of the following two generic interfaces
GenericPreloader
https://github.com/PowerLoom/pooler/blob/5e7cc3812074d91e8d7d85058554bb1175bf8070/snapshotter/utils/callback_helpers.py#L109-L126
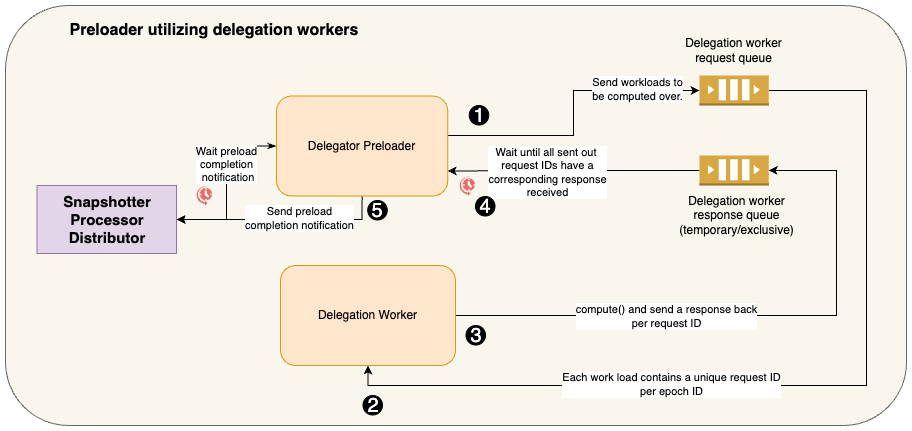
GenericDelegatorPreloader. Such preloaders are tasked with fetching large volumes of data and utilize delegated workers to which they submit large workloads over a request queue and wait for the results to be returned over a response queue.
https://github.com/PowerLoom/pooler/blob/5e7cc3812074d91e8d7d85058554bb1175bf8070/snapshotter/utils/callback_helpers.py#L129-L161
The preloaders can be found in the snapshotter/utils/preloaders directory. The preloaders that are available to project configuration entries are exposed through the config/preloader.json configuration.
https://github.com/PowerLoom/snapshotter-phase2-configs/blob/zkevm_with_remote_pinning/preloader.json#L1-L27
At the moment, we have 3 generic preloaders built into the snapshotter template.
- Block Details - It prefetches and stores block details for blocks in each Epoch and stores it in Redis
- Eth Price - It prefetches and stores ETH price for blocks in each Epoch and stores it in redis
- Tx Receipts - It prefetches all transaction details present in each Epoch and stores the data in Redis. Since fetching all block transactions is a lot of work, it utilizes the delegated workers architecture to parallelize and fetch data in a fast and reliable way
More preloaders can be easily added depending on the use case user is snapshotting for. It is as simple as writing logic in preloader.py, adding the preloader config to config/preloader.json, and adding the preloader dependency in config/projects.json
### Base Snapshot Generation
Workers, as mentioned in the configuration section for config/projects.json, calculate base snapshots against this epochId which corresponds to collections of state observations and event logs between the blocks at height in the range [begin, end].
The data sources are determined according to the following specification for the projects key:
- an empty array against the
projectsindicates no specific data source is defined - an array of EVM-compatible wallet address strings can also be listed
- an array of “
_ " strings that denote the relationship between two EVM addresses (for eg ERC20 balance of `addr2` against a token contract `addr1`) - data sources can be dynamically added on the protocol state contract which the processor distributor syncs with:
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/processor_distributor.py#L596-L599
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/processor_distributor.py#L408-L418
The project ID is ultimately generated in the following manner:
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/utils/snapshot_worker.py#L29-L38
The snapshots generated by workers defined in this config are the fundamental data models on which higher-order aggregates and richer data points are built. The SnapshotSubmitted event generated on such base snapshots further triggers the building of sophisticated aggregates, super-aggregates, filters, and other data composites on top of them.
Bulk Mode
For situations where data sources are constantly changing or numerous, making it impractical to maintain an extensive list of them, the Snapshotter Peer offers a Bulk Mode. This feature is particularly useful in scenarios where specific data sources need not be defined explicitly.
In Bulk Mode, the system monitors all transactions and blocks without the need for predefined data sources. The Processor Distributor generates a SnapshotProcessMessage with bulk mode enabled for each project type. When snapshot workers receive this message, they leverage preloaded transaction receipts for entire blocks, filtering out relevant transactions to generate snapshots for all data sources that interacted with the blockchain during that epoch. Snapshot worker then generates relevant project Ids for these snapshots and submits them for further processing.
Bulk Mode is highly effective in situations where the project list is continually expanding or where snapshots don’t need to be submitted in every epoch, perhaps because the data hasn’t changed significantly. Example use cases include monitoring on-chain activities and tracking task or quest completion statuses on the blockchain.
An important advantage of Bulk Mode is that, since all transaction receipts are preloaded, this approach can efficiently scale to accommodate a large number of project types with little to no increase in RPC (Remote Procedure Call) calls.
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/utils/snapshot_worker.py#L193-L212
### Data source signaling
As seen above in the section on base snapshot generation, data sources can be dynamically added to the contract according to the role of certain peers in the ecosystem known as ‘signallers’. This is the most significant aspect of the Powerloom Protocol ecosystem apart from snapshotting and will soon be decentralized to factor in on-chain activity, and market forces and accommodate a demand-driven, dynamic data ecosystem.
In this present implementation of the wallet boost use case, such sources are added for either the boost:eth_getBalance or boost:erc20_balanceOf project types as seen in the pre-supplied projects configuration file, where the projects key corresponding to the data sources are left as empty.
Every time a new project is added for either of these two types on the protocol state smart contract by an off-chain data source-detector and signaller, a ProjectUpdated event is emitted according to the following data model
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/utils/models/data_models.py#L102-L105
The snapshotting for every such dynamically added project is initiated only when the epochId, corresponding to the field enableEpochId contained within the ProjectUpdated event, is released. The processor distributor correctly triggers the snapshotting workflow for such dynamically added data sources in the following segment:
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/processor_distributor.py#L383-L399
### Snapshot Finalization
All snapshots per project reach consensus on the protocol state contract which results in a SnapshotFinalized event being triggered.
event SnapshotFinalized(uint256 indexed epochId, uint256 epochEnd, string projectId, string snapshotCid, uint256 timestamp);
Aggregation and data composition - snapshot generation of higher-order data points on base snapshots
Workers as defined in config/aggregator.json are triggered by the appropriate signals forwarded to Processor Distributor corresponding to the project ID filters as explained in the Configuration section. This is best seen in action in Pooler, the snapshotter implementation that serves multiple aggregated data points for Uniswap v2 trade information.
In case of aggregation over multiple projects, their project IDs are generated with a combination of the hash of the dependee project IDs along with the namespace
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/utils/aggregation_worker.py#L116-L124
Major Components
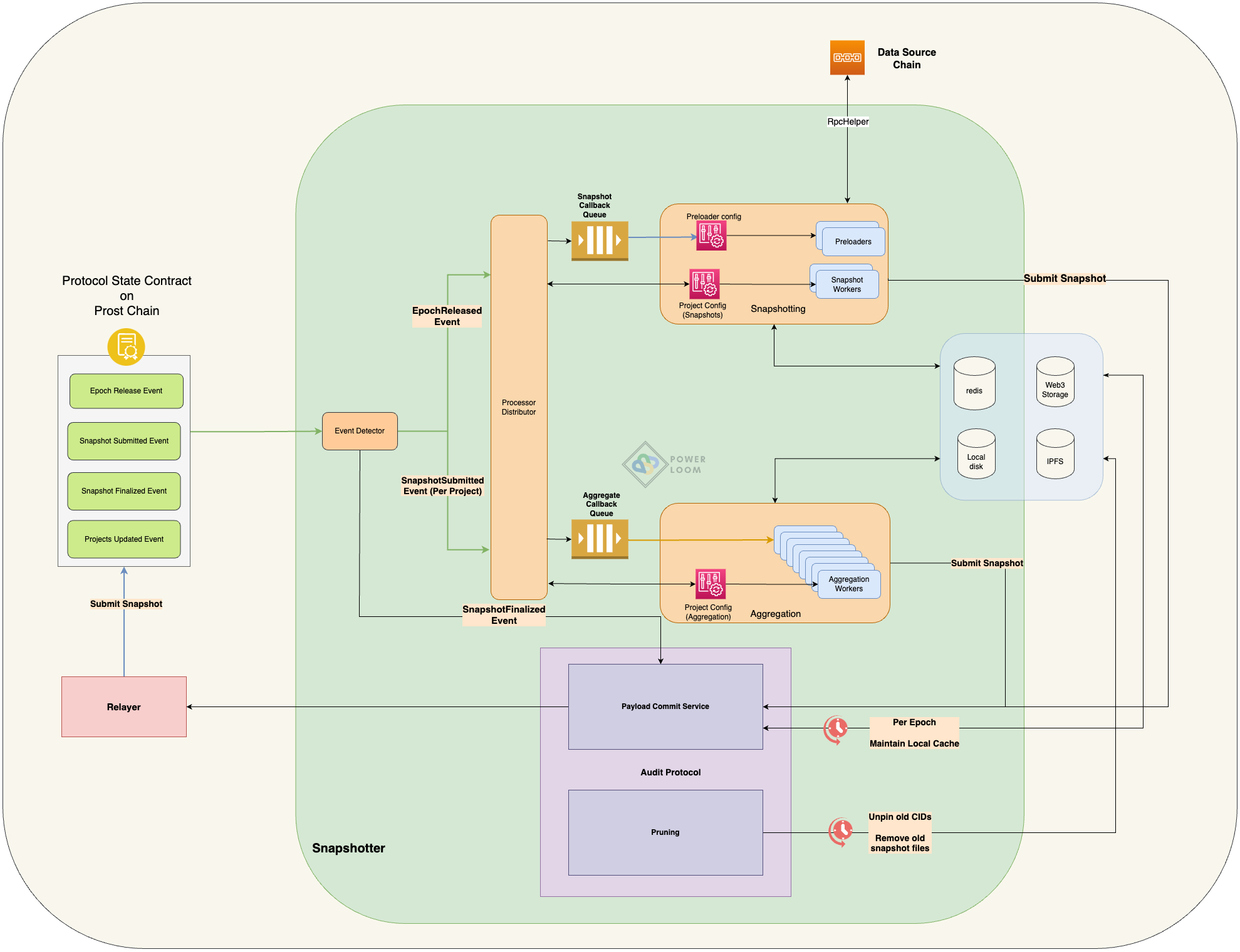
System Event Detector
The system event detector tracks events being triggered on the protocol state contract running on the anchor chain and forwards it to a callback queue with the appropriate routing key depending on the event signature and type among other information.
Related information and other services depending on these can be found in previous sections: State Transitions, Configuration.
Process Hub Core
The Process Hub Core, defined in process_hub_core.py, serves as the primary process manager in the snapshotter.
- Operated by the CLI tool
processhub_cmd.py, it is responsible for starting and managing theSystemEventDetectorandProcessorDistributorprocesses. - Additionally, it spawns the base snapshot and aggregator workers required for processing tasks from the
powerloom-backend-callbackqueue. The number of workers and their configuration path can be adjusted inconfig/settings.json.
Processor Distributor
The Processor Distributor, defined in processor_distributor.py, is initiated using the processhub_cmd.py CLI.
- It loads the preloader, base snapshotting, and aggregator config information from the settings file
- It reads the events forwarded by the event detector to the
f'powerloom-event-detector:{settings.namespace}:{settings.instance_id}'RabbitMQ queue bound to a topic exchange as configured insettings.rabbitmq.setup.event_detector.exchange(code-ref: RabbitMQ exchanges and queue setup in pooler) - It creates and distributes processing messages based on the preloader configuration present in
config/preloader.json, the project configuration present inconfig/projects.jsonandconfig/aggregator.json, and the topic pattern used in the routing key received from the topic exchange- For
EpochReleasedevents, it forwards such messages to base snapshot builders for data source contracts as configured inconfig/projects.jsonfor the current epoch information contained in the event. https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/processor_distributor.py#L125-L141 - For
SnapshotSubmittedevents, it forwards such messages to single and multi-project aggregate topic routing keys. https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/processor_distributor.py#L228-L303
- For
Delegation Workers for preloaders
The preloaders often fetch and cache large volumes of data, for eg, all the transaction receipts for a block on the data source blockchain. In such a case, a single worker will never be enough to feasibly fetch the data for a timely base snapshot generation and subsequent aggregate snapshot generations to finally reach a consensus.
Hence such workers are defined as delegate_tasks in config/preloader.json and the process hub core launches a certain number of workers as defined in the primary settings file, config/settings.json under the key callback_worker_config.num_delegate_workers.
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/config/preloader.json#L19-L25
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/config/settings.example.json#L86-L90
Delegation workers operate over a simple request-response queue architecture over RabbitMQ.
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/init_rabbitmq.py#L63-L72
One of the preloaders bundled with this snapshotter peer is tasked with fetching all the transaction receipts within a given epoch’s block range and because of the volume of data to be fetched it delegates this work to a bunch of delegation worker
- The Preloader: snapshotter/utils/preloaders/tx_receipts/preloader.py.
- The Delegation Workers: snapshotter/utils/preloaders/tx_receipts/delegated_worker/tx_receipts.py
As a common functionality shared by all preloaders that utilize delegate workers, this logic is present in the generic class DelegatorPreloaderAsyncWorker that all such preloaders inherit. Here you can observe the workload is sent to the delegation workers
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/utils/generic_delegator_preloader.py#L74-L98
Upon sending out the workloads tagged by unique request IDs, the delegator sets up a temporary exclusive queue to which only the delegation workers meant for the task type push their responses.
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/utils/generic_delegator_preloader.py#L100-L120
The corresponding response being pushed by the delegation workers can be found here in the generic class DelegateAsyncWorker that all such workers should inherit from:
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/utils/delegate_worker.py#L58-L69
Callback Workers
The callback workers are the ones that build the base snapshot and aggregation snapshots and as explained above, are launched by the process hub core according to the configurations in aggregator/projects.json and config/aggregator.json.
They listen to new messages on the RabbitMQ topic exchange as described in the following configuration, and the topic queue’s initialization is as follows.
https://github.com/PowerLoom/snapshotter-phase2-configs/blob/ddb4eba16b282fdf4c7211e17b4291fba942982a/settings.example.json#L42-44
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/init_rabbitmq.py#L118-L140
Upon receiving a message from the processor distributor after preloading is complete, the workers do most of the heavy lifting along with some sanity checks and then call the compute() callback function on the project’s configured snapshot worker class to transform the dependent data points as cached by the preloaders to finally generate the base snapshots.
RPC Helper
Extracting data from the blockchain state and generating the snapshot can be a complex task. The RpcHelper, defined in utils/rpc.py, has a bunch of helper functions to make this process easier. It handles all the retry and caching logic so that developers can focus on efficiently building their use cases.
Core API
This component is one of the most important and allows you to access the finalized protocol state on the smart contract running on the anchor chain. Find it in core_api.py.
The pooler-frontend that serves the Uniswap v2 dashboards hosted by the PowerLoom foundation on locations like https://uniswapv2.powerloom.io/ is a great example of a frontend specific web application that makes use of this API service.
Among many things, the core API allows you to access the finalized CID as well as its contents at a given epoch ID for a project.
The main endpoint implementations can be found as follows:
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/core_api.py#L186-L268 https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/core_api.py#L273-L324
The first endpoint in GET /last_finalized_epoch/{project_id} returns the last finalized EpochId for a given project ID and the second one is GET /data/{epoch_id}/{project_id}/ which can be used to return the actual snapshot data for a given EpochId and ProjectId.
These endpoints along with the combination of a bunch of other helper endpoints present in Core API can be used to build powerful Dapps and dashboards.
You can observe the way it is used in pooler-frontend repo to fetch the dataset for the aggregate projects of top pairs trade volume and token reserves summary:
try {
response = await axios.get(API_PREFIX+`/data/${epochInfo.epochId}/${top_pairs_7d_project_id}/`);
console.log('got 7d top pairs', response.data);
if (response.data) {
for (let pair of response.data.pairs) {
pairsData7d[pair.name] = pair;
}
} else {
throw new Error(JSON.stringify(response.data));
}
}
catch (e){
console.error('7d top pairs', e);
}
Development setup and instructions
These instructions are needed to run the system using build-docker.sh.
Configuration
Pooler needs the following config files to be present
settings.jsoninpooler/auth/settings: Changes are trivial. Copyconfig/auth_settings.example.jsontoconfig/auth_settings.json. This enables an authentication layer over the core API exposed by the pooler snapshotter.- settings files in
config/config/projects.json: Each entry in this configuration file defines the most fundamental unit of data representation in Powerloom Protocol, that is, a project. It is of the following schema{ "project_type": "zkevm:bungee_bridge", //An empty array indicates the data sources are to be loaded from the protocol state contract //If the project's key is missing, the snapshot build does not depend on a singular data source (for eg, an Ethereum block that is finalized) //It otherwise can be an array of EVM address strings or, // an array of "<addr1>_<addr2>" strings that denote the relationship between two EVM addresses (for eg ERC20 balance of `addr2` against a token contract `addr1`) "projects":[ ], "preload_tasks":[ "block_transactions" ], "processor":{ "module": "snapshotter.modules.boost.bungee_bridge", "class_name": "BungeeBridgeProcessor" } }Copy over
config/projects.example.jsontoconfig/projects.json. For more details, read on in the use case study for this current implementation.-
To begin with, you can keep the workers and contracts as specified in the example files.
config/settings.json: This is the primary configuration. We’ve provided a settings template inconfig/settings.example.jsonto help you get started. Copy overconfig/settings.example.jsontoconfig/settings.json. There can be a lot to fine tune but the following are essential.instance_id: This is the unique public key for your node to participate in consensus. It is currently registered on approval of an application (refer deploy repo for more details on applying).namespace, is the unique key used to identify your project namespace around which all consensus activity takes place.- RPC service URL(s) and rate limit configurations. Rate limits are service provider specific, different RPC providers have different rate limits. Example rate limit config for a node looks something like this
"100000000/day;20000/minute;2500/second"rpc.full_nodes: This will correspond to RPC nodes for the chain on which the data source smart contracts live (for eg. Ethereum Mainnet, Polygon Mainnet, etc).anchor_chain_rpc.full_nodes: This will correspond to RPC nodes for the anchor chain on which the protocol state smart contract lives (Prost Chain).protocol_state.address: This will correspond to the address at which the protocol state smart contract is deployed on the anchor chain.protocol_state.abiis already filled in the example and already available at the static path specifiedpooler/static/abis/ProtocolContract.json
Monitoring and Debugging
Login to the pooler docker container using docker exec -it deploy-boost-1 bash (use docker ps to verify its presence in the list of running containers) and use the following commands for monitoring and debugging
- To monitor the status of running processes, you simply need to run
pm2 status. - To see all logs you can run
pm2 logs - To see logs for a specific process you can run
pm2 logs <Process Identifier> - To see only error logs you can run
pm2 logs --err
For Contributors
We use pre-commit hooks to ensure our code quality is maintained over time. For this contributors need to do a one-time setup by running the following commands.
- Install the required dependencies using
pip install -r dev-requirements.txt, this will set up everything needed for pre-commit checks. - Run
pre-commit install
Now, whenever you commit anything, it’ll automatically check the files you’ve changed/edited for code quality issues and suggest improvements.
Phase 2 Quests: A Case Study of Implementation
Phase 2 quests form a crucial part of the Powerloom testnet program, where we leverage Snapshotter Peers to monitor on-chain activities of testnet participants across various chains and protocols. These quests predominantly operate in Bulk Mode due to their one-time nature and the highly dynamic set of participants involved.
In this particular implementation of the peer, known as ‘Snapshotter’ in the Powerloom Protocol, we have successfully harnessed its capabilities to provide accurate metrics, verified through consensus, pertaining to fundamental data points. These metrics allow us to determine if and when a quest is completed by a testnet participant.
This case study serves as a testament to the effectiveness and versatility of the Snapshotter Peer in real-world scenarios, highlighting its ability to support complex use cases with precision and reliability.
Review: Base snapshots
The snapshot builders can be found under the snapshotter-specific implementation directory: snapshotter/modules/boost. Every snapshot builder must implement the interface of GenericProcessorSnapshot
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/utils/callback_helpers.py#L89-L106
compute()is the callback where the snapshot extraction and generation logic needs to be written. It receives the following inputs:epoch(current epoch details)redis(async redis connection)rpc_helper(RpcHelperinstance to help with any calls to the data source contract’s chain)
transformation_lambdasprovide an additional layer for computation on top of the generated snapshot (if needed). If thecompute()callback handles everything you can just settransformation_lambdasto[]otherwise pass the list of transformation function sequences. Each function referenced intransformation_lambdasmust have the same input interface. It should receive the following inputs -snapshot(the generated snapshot to apply the transformation on)address(contract address to extract data from)epoch_begin(epoch begin block)epoch_end(epoch end block)
compute() should return an instance of a Pydantic model which is in turn used by the payload commit service helper method to convert the data structure to a dict.
https://github.com/PowerLoom/pooler/blob/5892eeb9433d8f4b8aa677006d98a1dde0458cb7/snapshotter/utils/generic_worker.py#L133-L135
Looking at the pre-supplied example configuration of config/projects.json, we can find the following snapshots being generated
zkevm:bungee_bridge
Snapshot builder: snapshotter/modules/boost/eth_balance.py
https://github.com/PowerLoom/pooler/blob/4cc64b4abd5a4d4cfb0b512dd9932031bbf611ba/config/projects.example.json#L3-L14
Its preloader dependency is block_transactions as seen in the preloader configuration.
The snapshot builder then goes through all preloaded block transactions, filters out, and then generates relevant snapshots for wallet address that received funds from the Bungee Bridge refuel contract during that epoch.
https://github.com/PowerLoom/pooler/blob/4cc64b4abd5a4d4cfb0b512dd9932031bbf611ba/snapshotter/modules/boost/bungee_bridge.py#L25-L92